こんにちは @7riatsu です。
今回は、サーバーの開発をする上で必須知識と言っても過言ではないデータベースのインデックスについて調べてみました。
この記事を読むことで次の項目を理解できます。
- インデックスとは何か
- 大規模なサービス開発をする上で、インデックスを適切に使うことの重要性
- SQL が実行され、データアクセスするまでの流れ
- MySQL がどのようにインデックスを用いるか調べる方法
- 遅いクエリを生み出さないために押さえるべきポイント
なお、本記事は DeNA 21新卒×22新卒内定者 Advent Calendar 2021 の17日目の投稿です。
前提
今回、インデックスについて調べるにあたって議論の対象とするデータベースを MySQL としています。 データベースによって違いがある部分もあるため、その点ご留意ください。
インデックスとは
インデックスとは、特定のカラム値のある行をすばやく見つけるために使用するデータ構造のことです。
- インデックスが張られている場合: テーブルのシークする箇所を絞ることが可能
- インデックスが張られていない場合: テーブルの全てのレコードを参照する必要がある
MySQL ではほとんどのインデックスのデータ構造に B-tree というデータ構造が採用されています。B-tree はデータベースのインデックスに一般的に利用されるツリー型のデータ構造のことです。(B-tree の詳しい説明は今回触れません。) ※例外として MEMORY テーブルはハッシュインデックスもサポートしています。
現実世界におけるインデックスの例として「辞書」を考えてみます。辞書は通常、アルファベット順や五十音順にソートされ、末尾の索引(インデックス)にはどのページにどの単語が書かれているか記載してあります。探したい単語を最初のページから1ページずつ順番に探すよりも、末尾の索引を参照しどのページに探している単語が書かれているかを把握した上で探した方が早く情報に辿り着けることは明らかです。
データベースも現実世界と類似の挙動をします。インデックスがある場合は、インデックスファイルからデータファイルのどのあたりを参照したら良いかを絞れるため、高速な処理を実現できます。 逆に、インデックスがない場合は、データファイルのどのあたりを参照したら良いか絞れないため、テーブル全体をシークする必要があります。これはフルテーブルスキャンといい、最も時間のかかる処理です。
インデックスの重要性
サービスの規模が大きくなればなるほど、テーブルのレコード数は多くなり、インデックスを適切に使うことの重要性は増します。
例えばテーブルのレコード数が100行しかないサービスでは、フルテーブルスキャンをしたところでかかる処理時間はたかが知れています。むしろインデックスを利用するよりもテーブル全体をシークした場合の方がかかる時間が少ないことすらあります。
しかし、テーブルのレコード数がXX万~YY億行もあるサービスでは、フルテーブルスキャンをしてしまうと1クエリあたりにかかる計算資源(CPU やメモリなど)と処理時間が膨大となります。 そのような重たいクエリが短時間にたくさん発行されるとデータベースの負荷が高まり、データベース起因の障害発生の可能性が高まります。
大規模なサービスの開発・運用をする際は、インデックスを適切に利用することがより高水準で求められます。
SQL がデータアクセスするまでの流れとインデックスの仕組み
SQL がデータアクセスするまでの流れ
次に、SQL が実行され、データアクセスするまでの流れについてお伝えします。
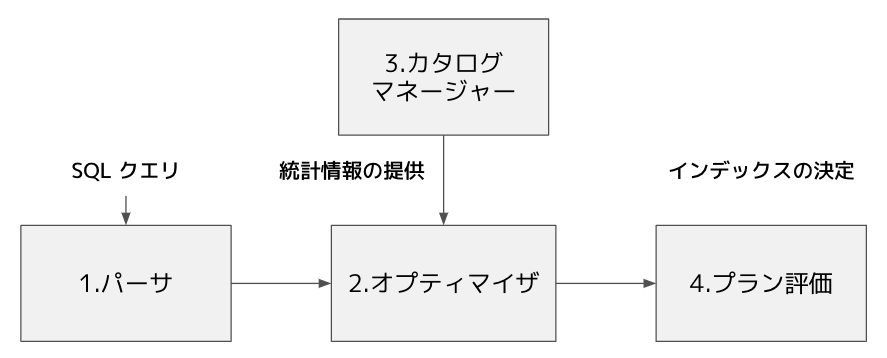
- 「パーサ」が構文解析を行いクエリを処理しやすい形に変換
- 「オプティマイザ」が「①選択可能な実行計画を複数作成し」「②各実行計画のコストを計算」する
- 「カタログマネージャー」がオプティマイザに統計情報を提供
- 「プラン評価」最適な実行計画を選択
1~4 について、それぞれもう少し深掘りして解説します。
1. パーサ
パーサでは SQL を構文解析し、MySQL が処理しやすい形に処理をします。この段階では、二つの役割を果たします。
まず一つ目は、入力された SQL が構文的に正しいか検証する役割です。構文的に誤った入力がされた場合、この段階で処理を打ち切ります。
次に二つ目は、入力された SQL を定型的な形に変換する役割です。これにより、効率的に以降の処理を MySQL が行えます。
2. オプティマイザ
オプティマイザでは最適なデータアクセスの方法を決定する役割を担います。オプティマイザは
- ①インデックスの有無やテーブルの統計情報などをもとに、選択可能な実行計画を複数作成し
- ②各実行計画のコストを計算
します。実行計画とは、使用するインデックスやテーブルの結合順序など、クエリを実行しデータアクセスする際の方法のことです。
オプティマイザがどのようにインデックスを使用してクエリを実行するか決定するため、とても重要な役割と言えます。
3. カタログマネージャ
カタログマネージャはオプティマイザが実行計画を立てるために必要な統計情報を提供します。
- 統計情報の例
- インデックス情報
- レコード数
- テーブルカラム内のNULLの数
- カーディナリティ(テーブルカラム内の異なる値の数)
4. プラン評価
プラン評価はオプティマイザの立てた複数の実行計画から、最適な実行計画を選択します。
MySQL がどのようにインデックスを用いるか調べる方法
ここまでの内容で、SQL が実行された際に MySQL がどのようインデックスを決定してデータアクセスするかを説明しました。 ここからは、具体的に MySQL がどのようにインデックスを決定するか調べる方法について説明していきます。
EXPLAIN
EXPLAIN とは MySQL がクエリをどのように実行するかを調べるためのステートメントです。
MySQL 5.6.3 以降は SELECT, UPDATE, DELETE, INSERT, REPLACE ステートメントにおいて EXPLAIN を実行できます。
これらのステートメントにおいて EXPLAIN を先頭につけて実行すると、MySQL はオプティマイザからの実行計画に関する情報を表示します。 開発をするときに実行されるクエリを EXPLAIN してみて、インデックスが適切に用いられるクエリになっているかを確認するようにしましょう。
例えば、users テーブルに対して created_at が 2021年12月1日 以降に作成されたデータを取得するクエリを投げる場合に使われるインデックスを調べたい場合は、以下のように SELECT ステートメントの前に EXPLAIN を追加して実行します。
EXPLAIN SELECT * FROM users WHERE created_at >= '2021-12-01T00:00:00+09:00';前提として、オプティマイザは統計情報を用いて実行計画を立てるので、本番環境または本番環境と同様のデータが入っている環境で EXPLAIN する必要があります。 そうしなければ、本番環境でクエリが実行される際に想定と異なる挙動をすることがあります。
実際に自分が遭遇した現象として、少ないデータ数しかない開発環境上で EXPLAIN をしたところ、インデックスが想定通りの挙動をせず、適切に使われていませんでした。 これは、データ数が少なすぎると、インデックスを用いずにクエリを実行した方が実行効率が良く、EXPLAIN にもインデックスを用いない実行計画の情報が表示されることがあるためです。 本番環境上で同様のクエリに対して EXPLAIN をしたところ、想定通りのインデックスが用いられていることを確認できました。
正しい結果を得るために、本番環境または本番環境と同様のデータが入っている環境で EXPLAIN するようにしましょう。
EXPLAIN の見方
EXPLAIN をした際に表示される項目は以下の通りです。(出典: MySQL 8.0 リファレンスマニュアル)
| カラム | 説明 |
|---|---|
| id | SELECT 識別子 |
| select_type | SELECT の種類 |
| table | 出力行のテーブル |
| partitions | 一致するパーティション |
| type | 結合型 |
| possible_keys | 選択可能なインデックス |
| key | 実際に選択されたインデックス |
| key_len | 選択されたキーの長さ |
| ref | インデックスと比較されるカラム |
| rows | 調査される行の見積もり |
| filtered | テーブル条件によってフィルタ処理される行の割合 |
| Extra | 追加情報 |
一つ一つの項目については今回触れないので、気になる方は出典元の 「MySQL 8.0 リファレンスマニュアル」 を参照してください。
この中で普段開発する時に見ると良さそうなところをピックアップします。
type
テーブルの結合方法を示します。
最も適切なものから不適切なものにかけて代表例を説明していきます。
| 種類 | 説明 |
|---|---|
| const | 一致するレコードが一行のみ。非常に高速。 |
| eq_ref | 結合時にインデックスの全てのパートが使用されており、かつインデックスは PRIMARY KEY または UNIQUE NOT NULL の場合。const の次の高速。 |
| ref | ユニークではないインデックスを用いて等価検索(WHERE)を行った場合。 |
| range | インデックスを用いて範囲検索(WHERE BETWEEN AND)した場合。 |
| index | インデックス全体をスキャンする場合。フルインデックススキャン。かなり遅い。 |
| ALL | テーブル全体をスキャンする場合。フルテーブルスキャン。最も遅い。 |
const, eq_ref, ref, range あたりが出ていれば大丈夫そうです。逆に index, ALL が表示されている場合はクエリを見直すかテーブル設計を見直す必要がありそうです。
possible_keys
このテーブル内の行検索に使用可能なインデックスを示します。NULL が表示されている場合、関連するインデックスがないことを示します。
key
MySQL が実際に使用を決定したインデックスを示します。基本的に possible_keys のいずれかから選択される形となります。 ここに自分が意図した通りのインデックスが表示されていることを確認できれば大丈夫です。
key_len
MySQL が使用を決定したキーの長さ(バイト数)を示します。複合インデックスを利用している場合、ここを見ることで、どの部分までインデックスを用いるか確認できます。
例えば、id(BIGINT), user_id(BIGINT) の複合インデックスを用いたい場合は BIGINT のバイト数が 8 であることから、key_len が 16 になっていることを確認できれば大丈夫です。ここが 8 になっている場合は最初の id しか利用されず、user_id が利用されていない可能性があるので注意が必要です。
データサイズに関しては「MySQL 8.0 リファレンスマニュアル」を参照することで調べられます。
rows
MySQL がクエリを実行するために調査する必要があると考える行数です。ここが大きければ大きいほど時間がかかってしまうので適切な行数になっているかどうか確認しましょう。
Extra
MySQL がクエリを解決する方法に関する追加情報を示します。表示される可能性のある表示項目の代表例を説明していきます。
| 表示項目 | 説明 |
|---|---|
| Using where | WHERE ステートメントに検索条件が指定されている場合に表示される。 |
| Using index | クエリがインデックスツリーの情報のみを使用して、テーブルからカラム情報が取得される。 |
| Using filesort | これが表示されると MySQL はソート順で行を取得する方法を見つけるために、インデックスを使用してクエリを解決できない。そのため、非常に時間がかかる可能性がある。 |
| Using temporary | クエリを解決するために一時テーブルを作成する必要があり、非常に時間がかかる可能性がある。 |
クエリを高速にしたい場合は Using filesort および Using temporary の値に気をつける必要があります。
Using filesort は ORDER BY をする際に、クイックソートを実行します。ソートバッファに収まる程度のデータ量であればメモリ内での処理なので極端に遅くなることはありませんが、メモリ内での処理ができないほどのデータ量になると一時テーブルを作成し、メモリと併用するようになります。ファイルの I/O 処理は一般的にメモリ処理と比べると時間がかかります。
Using temporary は一時テーブルを作成して処理を行います。初めは一時テーブルを Using filesort と同様にメモリー内に保持して処理しますが、データ量が大きくなるとディスク上に格納して処理します。この処理も同様に時間がかかります。
Using filesort および Using temporary が表示されている場合は改善を試みましょう。
終わりに
今回の記事では以下のことを取り上げました。
- インデックスとは何か
- 大規模なサービス開発をする上で、インデックスを適切に使うことの重要性
- SQL が実行され、データアクセスするまでの流れ
- MySQL がどのようにインデックスを用いるか調べる方法
- 遅いクエリを生み出さないために押さえるべきポイント
これらを理解して、必要最小限のクエリのみが発行されるように開発を心がけると良さそうです。
この記事を読んで「面白かった」「学びがあった」と思っていただけた方、よろしければ Twitter やはてなブックマークにてコメントをお願いします!
また、DeNA 公式 Twitter アカウント @DeNAxTechでは、 Blog記事だけでなく色々な勉強会での登壇資料も発信しているのでぜひフォローして下さい。